Matthias Töwe
Stefan Gradmann, Professor an der Katholieke Universiteit Leuven, eröffnete sein Referat an der Zentralbibliothek Zürich, dessen Thema bei anderer Gelegenheit noch plakativer mit „Container, Content, Context“ überschrieben wurde, mit der Beschreibung der ursprünglichen Einheit von Wissensproduktion bzw. -publikation und Wissensmanagement. Erst mit der Ausbreitung des Buchdrucks hätten sich die Rollen getrennt, die „Gutenberg-Klammer“ (einleuchtender wäre vielleicht „Gutenberg-Schere“), habe sich geöffnet: Während es zunehmend die Verleger waren, die sich mit den Autoren und den von ihnen produzierten Inhalten auseinandersetzten, hätten sich Bibliotheken auf die Verwaltung der physischen „Publikationscontainer“ – also der Bücher – beschränkt.
Das Web als Überwindung der Gutenberg-Schere
Im Kontinuum des World Wide Web lösen sich sowohl der lineare Publikationsprozess als auch der monolithische Dokumentbegriff des Buchdruckes auf. Dies eröffne neue Möglichkeiten für die Vernetzung von einzelnen inhaltlichen Elementen ohne Einschränkungen durch statische „Container“, also Dokumente. Technisch wird dies realisiert durch die Verwendung von RDF-Tripeln (Resource Description Framework[1]), die gemäss einem RDF-Schema „grammatikalisch verbunden“ werden. Ein RDF-Tripel drückt mit Hilfe der drei Bausteine Subjekt – Prädikat – Objekt Beziehungen zwischen im Prinzip beliebig kleinteiligen Inhaltsbausteinen aus. Da diese Tripel in vielfacher Weise miteinander verbunden sind, entsteht ein Netz semantischer Aussagen, die maschinell zu logischen Schlüssen verarbeitet werden können.
Damit eröffnet sich die Möglichkeit zu einem „semantischen Publizieren“, bei dem Dokumente im Extremfall nur noch als Aggregation von RDF-Tripeln verstanden werden und schliesslich auch die Unterscheidung zwischen Daten und Publikationen obsolet werden könnte. Offene Fragen betreffen dabei z.B. die Grenzziehung zwischen den einzelnen „Aggregaten“ angesichts der intensiven Vernetzung sowie Fragen der Provenienz: Welche Elemente waren zu welchem Zeitpunkt mit welchen anderen verbunden?
Europeana als „semantische Wolke“
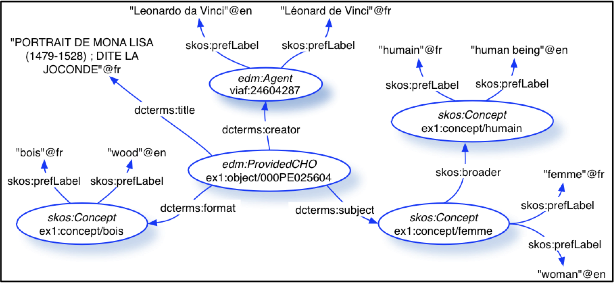
Stefan Gradmann zeigte verschiedene Beispiele semantischer Netzwerke oder Wolken, die auf jeden Fall eindrücklich sind, deren praktischer Nutzen aber auch für ihn noch nicht klar ist. Unmittelbar einleuchtend waren z.B. semantische Wolken, die aufzeigten, welche Autoren mit welchen anderen Personen in Kontakt standen oder von ihnen beeinflusst wurden – aber wie arbeitet man damit?
Als konkrete Anwendung aus bibliothekarischer Sicht stellte er das Europeana Data Model[2] (EDM) vor, das einerseits Repräsentationsformen von Objekten der Europeana (http://www.europeana.eu/) beschreibt und andererseits deren Kontextualisierung. Europeana habe sich bewusst vom ursprünglich gewählten Namen „European Digital Library“ getrennt, weil der Begriff einer als statisch und linear verstandenen Bibliothek als zunehmend weniger angemessen empfunden wurde. Auch verfüge Europeana nicht über einen klassischen Katalog, sondern ihr Konzept umfasse eine Objektschicht und eine semantische Datenschicht, in und zwischen denen freizügig navigiert werden könne.
Bibliotheken: Aktivere Rolle bei der Wissenserzeugung statt Dienstleister
Angesichts der schieren Informationsmasse und der wachsenden technischen Möglichkeiten – und damit auch Anforderungen – würden wissenschaftliche Autorinnen und Autoren vermehrt Unterstützung im Prozess der Wissensproduktion und –publikation benötigen.[3] Hier liege eine grosse Chance für Bibliothekarinnen und Bibliothekare.
Auf der anderen Seite müssten Bibliotheken sich von traditionellen Gewohnheiten trennen: Der „Katalog“ sei als Konzept überholt, da er zu statisch und linear funktioniere. Auch der in sich abgeschlossene „Bestand“ sei als Denkfigur problematisch und schliesslich sei die „Bibliothek“ sowohl als Begriff wie als Institution (im traditionellen Verständnis) in Frage zu stellen.
Bemerkenswert ist in diesem Zusammenhang die Aussage, Bibliotheken würden sich heute zu stark als reine Dienstleister betrachten, als solche seien sie aber über kurz oder lang durch effizientere Anbieter bedroht. In der Zukunft sollten Bibliothekarinnen und Bibliothekare unter Nutzung der oben beschriebenen technischen und inhaltlichen Möglichkeiten (wieder) eine aktive Rolle bei der Wissenserzeugung spielen und auf Augenhöhe mit Wissenschaftlerinnen und Wissenschaftlern arbeiten. Eine spezielle neue Nutzergruppe könne mit den „Digital Humanities“, also den mit digitalen Methoden arbeitenden Geisteswissenschaften, erreicht werden, denen neue Ansätze oder sogar völlig neue Methoden geboten werden könnten.[4]
In der folgenden Diskussion kamen weitere Aspekte zur Sprache:
- Die Frage, wie viele Bibliotheken in dieser neuen Rolle Platz finden (können), blieb offen. Bibliothekarische Thesauri seien zwar wegen ihrer hohen Qualität begehrte Datenquellen, aber es sei nicht das Ziel, einfach möglichst viele Daten zu sammeln, da dann zunehmend problematische Redundanzen aufträten.
- Die Vorstellung des Netzes als „die eine Bibliothek“ sei zumindest nicht schnell erreichbar, da es an der entsprechenden Formalisierung und Stabilität des Wortschatzes fehle. Insbesondere die Geistes- und Sozialwissenschaften würden ihre Begrifflichkeiten und Konzepte regelmässig so grundlegend erneuern, dass die Kontextualisierung Brüche erfahren müsse. Voraussetzung sei zudem eigentlich ein universeller Zugang für alle zu allem, während real abgestufte „Privatheitsgrade“ nötig seien. Dies sei aufwändig und teuer und wohl am ehesten in Fächern möglich, in denen „viel Geld im System“ sei. Gemeint waren hier die biomedizinischen Wissenschaften.
- Eine urheberrechtskonforme Kennzeichnung von Inhalten sei möglich und könne als Teil der „Provenience“ (Herkunfts)-Information sogar zuverlässiger transportiert werden als heute. Auch Mechanismen für die Anerkennung wissenschaftlicher Arbeiten könnten mit den skizzierten Modellen differenzierter arbeiten, da z.B. zustimmende von ablehnenden Zitaten unterschieden werden könnten.
- Die Einführung von RDA (Resource Description and Access[5]) sei zumindest ein halber Schritt in die richtige Richtung, die neueste RDA-Version sei „RDF-transparent“. Davon abgesehen enthalte RDA aber zu viele Rückbezüge auf die klassische Katalogdenkweise und man könnte im Hinblick auf Linked Open Data mehr daraus machen. Dazu gebe es eine regelrechte Richtungsdiskussion in den beteiligten Institutionen.
- Als Voraussetzung zur Vorbereitung einer breiten Verankerung von Linked Open Data müssten die entsprechenden Konzepte mehr Platz in der Lehre erhalten, und zwar nicht nur in den informationswissenschaftlichen Fächern.
- Bibliotheken – oder wie sie dann zukünftig heissen würden – bräuchten mehr Personal mit entsprechender Spezialisierung, und gleichzeitig müssten sich mehr Spezialisten aus den jeweiligen wissenschaftlichen Domänen beteiligen. Dies sei jedoch arbeitsteilig möglich, wenn man nicht innerhalb starrer Institutionengrenzen denken würde. Fachwissenschaftler sollten sich jedoch nicht mit den Mechanismen der Kontextualisierung auseinandersetzen müssen – und gerade hier liege die Chance für die Bibliothekarinnen und Bibliothekare als Vermittler.
Fazit
Ein interessanter Vortrag, der mit seinen weitreichenden und letztlich auch überraschend einseitigen Visionen und Forderungen zur Diskussion auffordert. Für die nicht wirklich Eingeweihten [zu denen sich der Autor dieser Zeilen zählt] bleiben Fragen offen, die zum Teil dem unzureichenden Verständnis der Methoden geschuldet sind:
- Wie gross ist der Nutzen einer hochgradigen Vernetzung, die nur noch maschinell zu verarbeiten ist? Oder anders gefragt: Sind die potentiellen Kunden schon in grosser Zahl aktiv oder in absehbarer Zeit zu erwarten oder wird hier mit hohem Aufwand (zunächst?) nur eine Gruppe von technikaffinen Insidern bedient?
- Welche Voraussetzungen sind konkret von den Datenanbietern zu schaffen?
- Was sind die Nebenwirkungen gerade auch für das wissenschaftliche Arbeiten, wenn sich die Dokumente in gewissem Sinne „auflösen“ (dies ist zwar nicht zwingend, wird aber konzeptionell zumindest in Kauf genommen)?
- Wie ist aus wissenschaftlicher Sicht das Verhältnis zwischen der Erzeugung wirklich neuer Inhalte und der Dritt- und Viert-Nutzung vorhandener Daten zu bewerten?
- Sind es nicht auch in der skizzierten „neuen“ Landschaft vor allem Dienstleistungen, die wissenschaftliche Kundinnen und Kunden von den Bibliotheken erwarten? Welche Positionen im Wissenschaftsprozess sind wirklich für Institutionen zugänglich, die nicht selbst Forschung treiben (sollen)? Ist die postulierte Verschiebung des Selbstverständnisses von Bibliotheken als Dienstleister wirklich so gross und ist sie zwingend?
Es ist klar, dass solche und ähnliche Fragen in diesem Rahmen nicht beantwortet werden konnten. Sie sollten aber angesichts der Begeisterung für die theoretischen und praktischen Möglichkeiten neuer technischer Verfahren nicht ausser Acht gelassen werden, zumal wenn diese als im Grunde alternativlos dargestellt werden. Es wäre wichtig, dass mehr Bibliotheken aufgrund eigener Experimente und Erfahrungen aktiv und fundiert an der Diskussion der Chancen und Risiken teilnehmen könnten.
[1] Für eine kurze Einführung siehe z.B. http://de.wikipedia.org/wiki/Resource_Description_Framework, Zugriff am 06.05.2013.
[2] Zur Dokumentation auf „Europeana Professional“: http://pro.europeana.eu/edm-documentation
[3] Vorschläge für eine vertiefte Recherche: Semantic Abstracting, Named Entity Recognition, automatisierte Kontextualisierung sowie robuste Inferenzierungsmethoden.
[4] Zu den Möglichkeiten, die hier gemeint sind, siehe z.B. Stäcker, Thomas: Wie schreibt man Digital Humanities richtig? – Überlegungen zum wissenschaftlichen Publizieren im digitalen Zeitalter. Bibliotheksdienst 2013; 47(1): 24–50. http://dx.doi.org/10.1515/bd-2013-0005.
[5] Allgemeine Information: http://de.wikipedia.org/wiki/Resource_Description_and_Access